- Introduction
End in . SignUp Now

| Batch Schedule | Batch Duration | Frequency | Timing | Virtual Training |
|---|---|---|---|---|
| Start Date: 09/11/2021 | 30 Hours / 10 Session | |||
| Sun - Tue - Thu | 7.00 PM to 10.00 PM | Zoom | ||
| End Date: 30/11/2021 | Each Session 3 Hours |
Is It Possible to Crack UPDA MMUP Electrical Exam in 1st Attempt?
Our Training Pattern is designed in such a way that every Electrical engineer who gets enrolled in Our UPDA Electrical Master Course can get their UPDA Electrical Engineering License in their Very 1st Attempt.
63 Module Live Mock Test Series (As Per UPDA Qatar Exam Standard)
(From Previous Year UPDA Electrical Exam Questions (2014 – 2021))
(27 Questions on Each Module)
(Total 1701 Questions & Answers with Explanation)
UPDA Electrical 63 Modules Live Mock Test Series Customized from Previous Year UPDA Electrical Exam Questions (2014 – 2021) – Based on UPDA Qatar Exam Standard and Weightages on Electrical Engineering, Electronics and Communication Engineering, Instrumentation Engineering and Project Management Subjects with Detailed Result and Performance Analysis Report at the end of Each Module which helps to Increase Speed and Accuracy.
SkillXplore UPDA Electrical Mock Test Series helps you understand how the real UPDA Electrical Exam will be conducted, and you can expect the maximum number of questions from this 63 UPDA Electrical Mock Test Series in Your Real Time UPDA Qatar Electrical Exam. Because, Very Good thing In UPDA Qatar Exam is, they are asking Mostly Repeated Questions from Previous Year UPDA Qatar Exam Questions Electronics, Electrical, Instrumentation Engineering and Project Management which will definitely help you improve your scores and also in Cracking the UPDA Electrical Exam in 1st First Attempt.
This is the Smartest Way to Crack Your UPDA Electrical Engineering License on Your 1st Attempt in Qatar.
Let Our Experts Guide You in Your Preparation

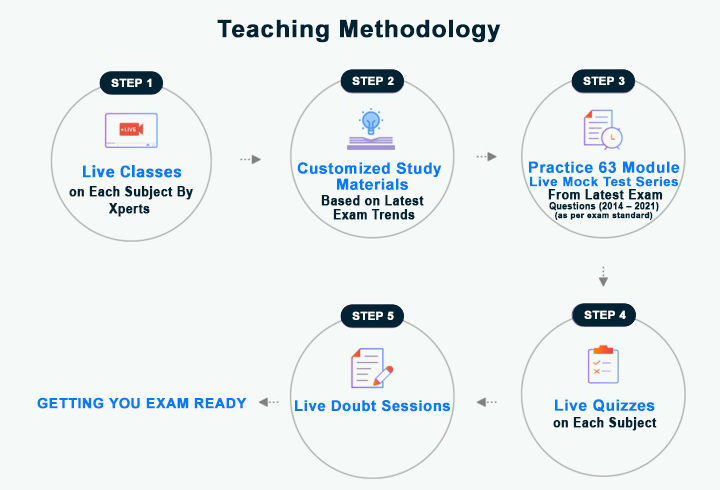
Chat with your educator, engage in discussions, ask your doubts, and answer polls - all while the class is going on.

All our courses are structured in line with your exam syllabus to help you best prepare for it

Customized Study Materials Based on Latest Exam Trends with conceptual clarity and better understanding. With this course, you can easily comprehend the vast syllabus in a short time.

From Latest Exam Questions (2014 to 2021) (as per exam standard)

Evaluate your preparation with our regular mock tests and quizzes and get detailed analysis on your performance.

One subscription gets you access to all our live and recorded courses to watch from the comfort of any of your devices.

Complete Documentation Support Including Upload Documents on Baladiya Website.

Contact Our Consultant (+974-77096396) to get Personalized Consultation For Your Exam.
#Prepare Smart With SkillXplore Master Course
Quality of the session
Ease of access to classes
Quality of e-book
User-friendly Platform
Engineer Engagement
Subject Expertise
Quality of Content
Clarification of doubts
Review
No Reviews

Verified learner
{{data.review_date}}
{{data.feedback}}
Was this review helpful?
+974-77096396
